Among the various focuses of this class was the topic of Feature Subset Selection, which is used to determine which of the various attributes of a given dataset best predict for a given class. (e.g. which of known weather conditions best predict if we will play golf today/choose the "yes" class)
A major topical paper on the subject of Feature Subset Selection was written by Mark A. Hall and Geoffrey Holmes in a paper called Benchmarking Attribute Selection Techniques for Discrete Class Data Mining. In this paper, they examine a variety of Feature Subset Selection algorithms and compare them using the WEKA tool. The results of their paper can be summarized with these statements from the conclusion of their paper:
"... for accuracy, Wrapper is the best attribute selection scheme, if speed is not an issue. Otherwise, CFS, consistency, and ReliefF are good overall performers. CFS chooses fewer features, is faster and produces smaller trees than the other two..."
In addition to Feature Subset Selection, this course has also covered the topic of Treatment Learning. Treatment Learning focuses on attempting to find particular ranges of attribute values that maximize the selection of a "best" class from a dataset. It combines ranges of attribute values to generate "treatments" that can be used to identify the best class in the future. The TAR2 and TAR3 treatment learners have been mentioned in this course; TAR3 for its independent use and TAR2 for its use with the TAR2 SELECT Algorithm.
The TAR2 SELECT Algorithm was introduced in a paper written from research completed for a previous edition of this course. The paper was entitled Learning Tiny Theories and was written by Menzies, Gunnalan, Appukutty, Srinivasan, and Hu. TAR2 SELECT took the premise of Treatment Learning and attempted to apply it to become a Feature Subset Selector. This was accomplished by using the TAR2 treatment learner to select treatments for each class of a dataset, and then to trim those treatments to just the attributes that they involved. These attributes were placed in a set that was used to trim the original dataset down to just the attributes that were important for SELECTing any particular class in the dataset. The algorithm for the TAR2 SELECT algorithm is:
The original version of SELECT (i.e. TAR2 SELECT) was implemented by hand and did not provide for a quick and easy means by which to recreate it. Recognizing this, we proposed to implement SELECT via a series of scripts that will be made available for future recreations. Additionally, we noted several inconsistencies in the original report, including that the authors had used a series of data from the Hall & Holmes paper that called for the use, in some cases, of fractional attributes. Additionally, the authors introduced a score for their algorithm, stating that their results would be considered better than the old if (a) the new theory was smaller (i.e. SELECTed fewer attributes) and (b) the new theory's accuracy was within a particular delta from original. In thier experiment, the delta was required to be below 3%. The paper did nothing to distinguish why three percent had been chosen. Investigating these occurrences were the motivation for our experiment.
The pseudocode for the TAR3 SELECT program suite is:
The TAR3 SELECT suite is written using several GAWK scripts controlled by a BASH script. While these languages are not overly complicated, some of the manipulation proved to be trying. To help others avoid those problems in the future (for other SELECT researchers), the TAR3 SELECT program suite is available in the form of a ZIP File
In order to prepare for our experiment with TAR3 SELECT, we gathered twenty-six data sets from the University of California Irvine Machine Learning Repository Repository. We processed the datasets into useable form; specifically, to .arff files that can be accessed and used by the WEKA. Recognizing the likelihood that some person or persons might possibly want to recreate this expiriment from these data sets, we have made them available to download in the form of a ZIP File. This file contains the original ARFF formatted files used to conduct the experiments.
Additionally, our results from TAR3 SELECTing these datasets are being made available so that a user who is not comfortable dealing with the code involved in TAR3 SELECT can still run the WEKA experiment. The TAR3 SELECT-trimmed datasets are available in the form of a ZIP File . Part of the TAR3 SELECT trimming process removes extraneous comments, which are available in the University of California Irvine Machine Learning Repository Repository in the form of .names and .info files.
In order to generate results for this experiment, the previously mentioned ARFF data files were run through the TAR3 SELECT program suite. This group of programs includes the scripts to run TAR3 SELECT itself, but also a program designed to take any properly formatted arff data files and from it produce the three files (.name, .cfg, and .data) that are required for TAR3, and also a program designed to produce trimmed versions of the original Arff files to only contain those attributes SELECTed by TAR3 SELECT. In regards to the .cfg file, the script accepts default values which are placed into each .cfg file. The defaults for our experiment were:
Number of Percentile Chops(granularity)=5
Maximum Number of Best Treatments(maxNumber)=1
Maximum Treatment Size(maxSize)=# of attributes
Random Number of Trials Before Evaluating Best Treatment(randomTrials)=50
Number of Random Trials Without a New Best Treatment Before Terminating(futileTrials)=5
Percentage of Data Instances that Must Be Contained By a Treatment(bestClass)=20%
Our original work was to read both papers and try to determine where the values from the Figures 14 and 15 of the Learning Tiny Theories paper had come from. From the reading, we determined that the non-SELECT results had been directly taken from the Hall & Holmes paper and inserted into these figures. No new calculations had been done to derive them. This was because the TAR2 SELECT group used the same datasets as the original paper
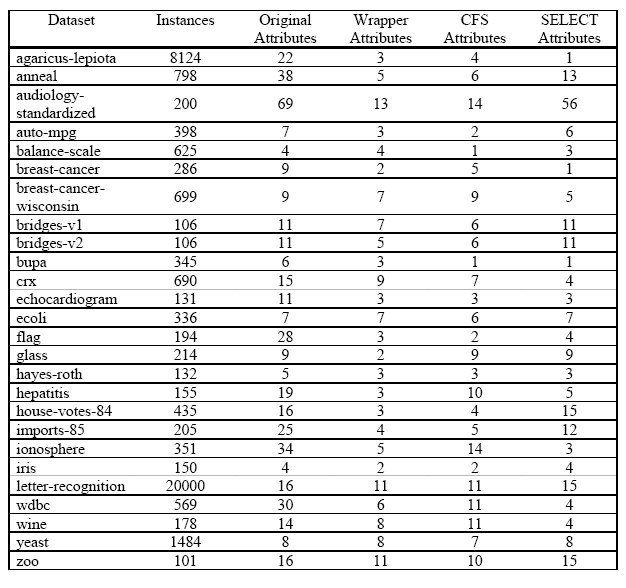
TAR3 SELECT was run on a mixture of datasets, some from the original TAR2 SELECT and some new. Results were also produced for the WRAPPER (around Naive-Bayes) and CFS. The results can be found in the table below:
We can see from this table that on certain datasets, TAR3 SELECT picked fewer attributes than its fellows. However, there are also instances where TAR3 SELECT performs much worse than the other Feature Subset Selectors. This may be due to the criteria used to trim the SELECT selections down. When attempting to prune, values had to be tweaked for some of the datasets to ensure that their SELECT subset contained any data items, while other datasets had many attributes exceeding the minimum number of occurrences required to appear in the trimmed dataset. We would recommend a more dynamic approach to such selection in future research.
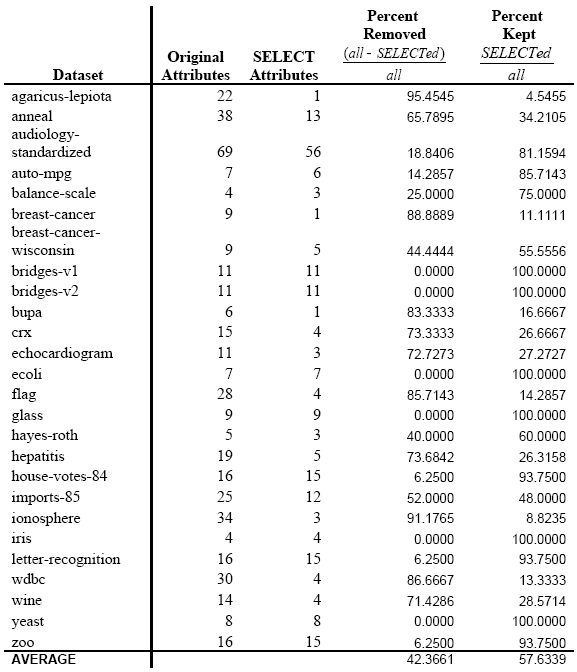
Examining the SELECTed datasets versus the original, we can see that in some (12 of 26) cases, TAR3 SELECT performed very well, removing at least 50% of the attributes from the original dataset. However, in 9 of 26 cases, TAR3 SELECT fails to remove more than 10% of the attributes from the original dataset, and in 6 of those cases, TAR3 SELECT fails to remove any attributes. Attempting to generalize the datasets which do not get SELECTed very well versus those that do based on class does not work well, since both groups have some datasets with two classes and some with 3 or more classes.
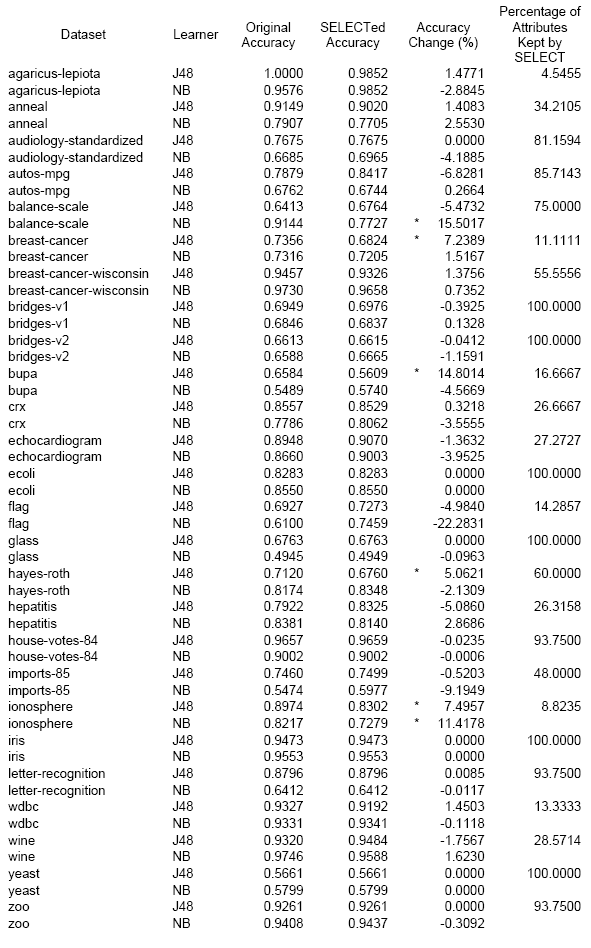
When comparing accuracy scores accross the J48 and Naive Bayes learners on the original and SELECTed datasets, there are some standout things to report. First, any row with an * (asterisk) in its accuracy change column would have failed the original delta test proposed in the Learning Tiny Theories paper. It is interesting to note that except in the cases of Naive Bayes run on the balance scale dataset and the case of J48 run on the hayes-roth dataset, that these failures occur when SELECT removes most of the original attributes. This would imply that perhaps we were right about previous assertions that our attribute pruning strategy may greatly affect the outcomes of the SELECT process and might be better if we can find a more dynamic approach.
Aside from the 6 of 52 cases that would have failed the original cut off criteria for acceptability in TAR2 SELECT, it is interesting to see that the Accuracy change column houses many negative values. Negative values indicate that our pruned dataset had a higher accuracy score than the original dataset. In some cases (10), that score is greater than 3%. It is interesting to note that most of those examples can be characterized by SELECT cutting at least 50% of the original attributes from consideration; however, the scores for the audiology dataset run through Naive Bayes and the autos-mpg dataset run through J48 both do so in datasets that are 80% in tact.
While this experiment does not entirely recreate the results viewed in the Learning Tiny Theories paper, it was an interesting step towards recreating that effect. The biggest point of contention that may make the results from our algorithm more closely mirror the original paper is the process by which attributes are SELECTed/rejected from the final dataset. We believe that our method is not the best possible, and that perhaps a more dynamic approach to this portion of the TAR3 SELECT process would lead to our attribute selection numbers more closely correlating with WRAPPER and CFS, while maintaining our healthy increase in accuracy in some datasets.
If future research is based on this project, the following items are recommended as areas of focus:
Also, a word to the wise for future researchers in this topic: There is a lot of post processing at the end of this experiment, which we have struggled with and as a result been unable to show. Expect lots of data that requires combing through when using the WEKA tool.