
(Reference: Science, 20 June 1980, Vol. 208. no. 4450, pp. 1335 - 1342 "Expert and Novice Performance in Solving Physics Problems", Jill Larkin, John McDermott, Dorothea P. Simon, and Herbert A. Simon. )
Much of the early AI research was informed by a cognitive psychology model of human expertise. The model has two parts:
Reasoning was, according to this mode: a match-act cycle:
In this model
Q: How to experts know what is relevant?
Much, much work on mapping this cognitive psychological insight into AI programs
(Reference: "An Expert System for Raising Pigs" by T.J. Menzies and J. Black and J. Fleming and M. Dean. The first Conference on Practical Applications of Prolog 1992 . Available from http://menzies.us/pdf/ukapril92.pdf )
PIGE: Australia's first exported rule-based expert systems
Written by me, 1987 who trapped the expertise of pig nutritionists in a few hundred rules.
( V.L. Yu and L.M. Fagan and S.M. Wraith and W.J. Clancey and A.C. Scott and J.F. Hanigan and R.L. Blum and B.G. Buchanan and S.N. Cohen, 1979, Antimicrobial Selection by a Computer: a Blinded Evaluation by Infectious Disease Experts, Journal of American Medical Association, vo. 242, pages 1279-1282)
Given patient symptoms, what antibiotics should be prescribed?
Approx 500 rules.
Extensively studied:
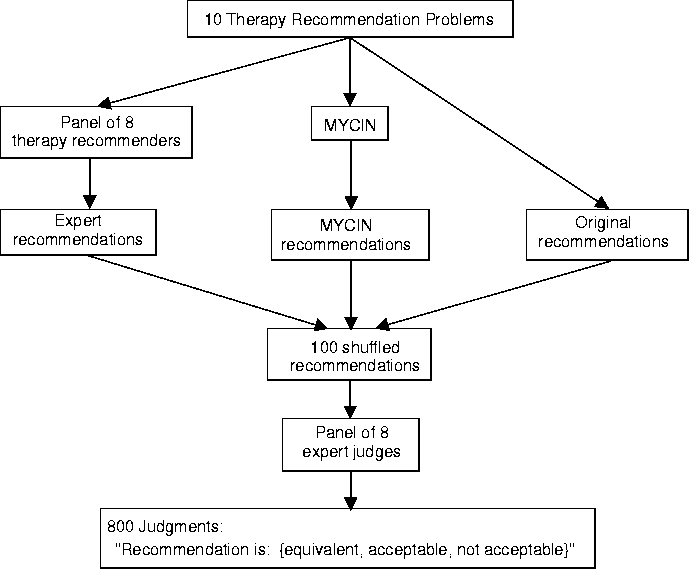
Compared to humans, performed very well:
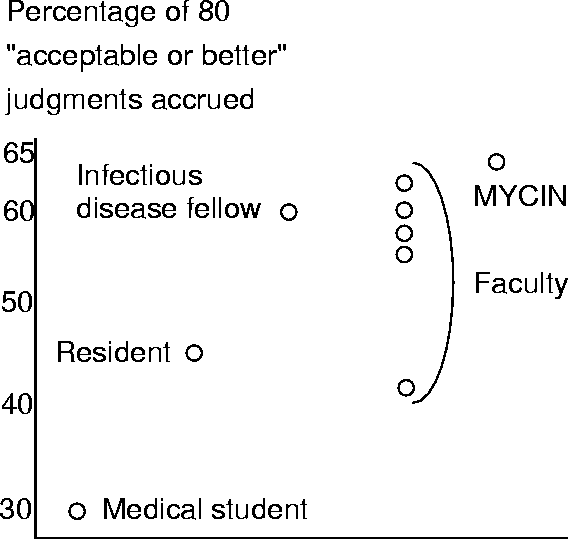
Why did it perform so well?
John McDermott, DEC, 1980s. Two systems:
With strong theoretical support and excellent industrial case studies, the future for AI seemed bright.
Begin the AI summer (mid-1980s). Just like the Internet bubble of 2000: fledging technology, over-hyped, immature tool kits.
And after the summer, came the fall. Enough said.
Happily, then came the 1990s, data mining, and results from real-time AI planners, and stochastic theorem provers.
By 2003, I could say I was an AI-nerd and people would not run away.
Here's a good introduction on rule-based programming. Read it (only pages 1,2,3,4,5,6,7) carefully to learn the meaning of:
Backward chaining supports how and why queries:
Forward chaining supports only how not why.
Define match, resolve, act
Some nice advantages for software engineering:
As rule-based programs became more elaborate, their support tools more intricate, the likelihood that they had any human psychological connection became less and less.
As we built larger and larger rule bases, other non-cognitive issues became apparent:
Note that both these problems come from the global nature of match: all rules over all working memory.
Go to simpler representations. e.g. state machines (used in gaming, next lecture)
As used in many rule-based tools including OPS5, ART, JESS. Compile all the rules into a big network wiring all the conditions together.
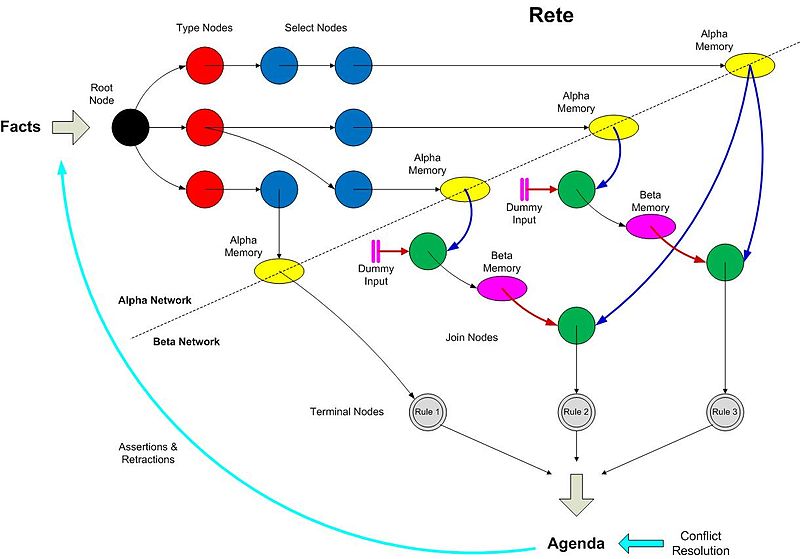
If searching/understanding all is too much, find ways to built the whole from local parts. Have separate rule bases for each part.
Q: How to divide the system?
E.g. here's Clancy's abstraction of MYCIN:

And here's his abstraction of an electrical
fault localization expert system:

Note that the same abstract problem solving method occurs in both
A whole mini-industry arose in the late 1980s, early 1990s defining libraries of supposedly reusable problem solving methods.
e.g. Here's "diagnosis"

Here's "monitoring":

Note that you could write and reuse rules based to handle select, compare, specify.
And there's some evidence that this is useful. Marcus and McDermott built rule bases containing 7000+ rules via role-limiting methods. That is, once they knew their problem solving methods, they write specialized editors that only let users enter in the control facts needed to just run those methods.
For a catalog of problem solving methods, see Cognitive Patterns By Karen M. Gardner (contributors James Odell, Barry McGibbon), 1998, Cambridge University Press
We study AI to learn useful tricks. Sometimes, we also learn something about people. Here's a radically different, and successful, method to the above. What does it tell us about human cognition?
Ripple-down rules is a maintenance technique for rule-based programs initially developed by Compton. Ripple-down rules are best understood by comparison with standard rule-based programming. In standard rule-based programming, each rule takes the form
rule ID IF condition THEN actionwhere condition is some test on the current case. In the 1970s and early 1980s rule-based systems were hailed as the cure to the ills of software and knowledge engineering. Rules are useful, it was claimed, since they: represent high-level logic of the system expressed in a simple form that can be rapidly modified.
However, as these systems grew in size, it became apparent that rules were surprisingly harder to manage. One reason for this was that, in standard rule-based programming, all rules exist in one large global space where any rule can trigger any other rule. Such an open architecture is very flexible. However, it is also difficult to prevent unexpected side-effects after editing a rule. Consequently, the same rule-based programs hailed in early 1980s (XCON) became case studies about how hard it can be to maintain rule-based systems.
Many researchers argued that rule authors must work in precisely constrained environments, lest their edits lead to spaghetti knowledge and a maintenance nightmare. One such constrained environment is ripple-down rules that adds an EXCEPT slot to each rule:
rule ID1 IF condition THEN EXCEPT rule ID2 THEN conclusion because EXAMPLE
Here, ID1,ID2 are unique identifiers for different rules; EXAMPLE is the case that prompted the creation of the rule (internally, EXAMPLEs conjunction of features); and the condition is some subset of the EXAMPLE, i.e., condition ⊆ EXAMPLE (the method for selecting that subset is discussed below). Rules and their exceptions form a ripple-down rule tree:

At run time, a ripple-down rule interpreter explores the rules and their exceptions. If the condition of rule ID1 is found to be true, the interpreter checks the rule referenced in the except slot. If ID2's rule condition is false, then the interpreter returns the conclusion of ID1. Else, the interpreter recurses into rule ID2.

(Note the unbalanced nature of the tree, most patches are shallow. This is a common feature of RDRs).
Ripple-down rules can be easier to read than normal rules:

But in practice, Compton advises hiding the tree behind a difference-list editor. Such an editor constrains rule authoring as follows:
condition2 = EXAMPLE1 - condition1 condition2 ⊆ EXAMPLE2
When users work in a difference list editor, they watch EXAMPLEs running over the ripple-down rules tree, intervening only when they believe that the wrong conclusion is generated. At that point, the editor generates a list of features to add to condition2 (this list is generated automatically from the above equations). The expert picks some items from this list and the patch rule is automatically to some leaf of the ripple-down rules tree.
Ripple-down rules are a very rapid rule maintenance environment. Compton et.al. report average rule edit times between 30 to 120 seconds for rule bases up to 1000 rules in size [Compton 2005]
AFAIK, ripple-down-rules are the current high-water mark in knowledge maintenance.
Q: what does this tell us about human knowledge?
{kind=link}