
Beyond Mining Repositories
XXXX as with all things, Holte and Rams. 1r cs C4.5 GAs vs TEAC which vs other learners and the koru heuristics tdidf vs pca genic vs k-means tar3 vs standard optimizersGoals

Q1:So, now you can mine software repositories. What else can you do?
- A1: everything.
- Data mining is about discovery.
- Rational being use discovery every day, in many ways.
- Study data mining to understand rationality (both it's application and it's mistakes)
Q2: Is too much data mining a bad thing (torturing the data)?
- A2: Yes indeed, mistakes can be made
- But learning is hard- all learning agents (including humans) make mistakes.
- What we need are:
- Continuous verification methods for our learners.
- A community of learners, shedding insights on each other.
Q3: Is data mining a complex task?
- A3: Yup. Lots of ways to do it.
- A4: Nope. There are shortcuts
In this talk, we expand on A1, A2, A3, A4.
TOE = A Theory of Everything
Let ,
,
be
a theory, goals, and some assumptions.
Let
there there exist some
predicate that can report inconsistent assumptions e.g.:
-
- or, perhaps more generally
Find the assumptions that satisfy rules one and two:
-
(do something)
-
(don't screw up)
What can we do with the above? Well....
Induction
If "Deduction
Ignore rule2;
when the assumptions
are known inputs; then and the goals
are the reachable outputs condonned by the theory
.
Abduction
Find all solutions to the above two equations and sort them into worlds- Each world
contains subsets:
- Each world
;
- Each world
.
(BTW, [Poole94] calls these worlds "scenarios" while [DeKleer86] called them "envisonments" ).
The
"best"
worlds (that will will use, somehow) are selected by
;
- So
;
Prediction
Prediction is deduction in each world.Verification
Also, if the goalsClassification
Classification is just prediction where
contains reserved atoms tagged as classifications
just deduction in each world (runs fast, see above).
Diagnosis
Diagnosis is selecting the world(s) that includes:
- all the observed faults (set-covering diagnosis)
- or the worlds consistent with the what ever contradicts the observed faults (consistency-based diagnosis) [Console91].
Probing
A related task to diagnosis is probing; i.e. the selected exploration of assumptions in order to rule out competing diagnosis. To implement this:- Count how many times an assumption appears in various worlds;
- Query the assumptions that appear in the fewest worlds.
Planning
If we have a
predicate, then planning is favoring the worlds with the least
cost.
Explanation
If we have a
model listing concepts that have been seen before, then the best explanation is that which
uses the most familiar concepts; i.e. the one that maximizes
More
For more on applications in this framework, see [Menzies96].
Warning: TOE is Slooooooow
We can make some comments about the complexity of the above:
-
If we ignore
- In general abduction is NP-hard [Bylander91].
- Certain restrictive specializations run much faster [Zanuttini03, Menzies02].
- However exponential runtimes curse many implementations; e.g. [Menzies99].
TOE and Data Mining
The above is silent how we find solutions to rules one and two. There are many ways to do this:
- Backward chaining (as done in THEORIST;
- Forward chaining (as done in the ATMS);
- A constraint solver [Kakas01];
- etc
What does the above look like in a data mining framework?
- Take a theory
;
- Exercise the theory to generate data
- We will assume that some subset of the data has been passed through some scoring function
(and if that function returns descrete values, will call that "score" a "classification".
- Apply a data miner to learn assumptions
Data Mining: A Bad Idea?
Data Mining
What is data mining? According to Fayyad96, it looks like this:
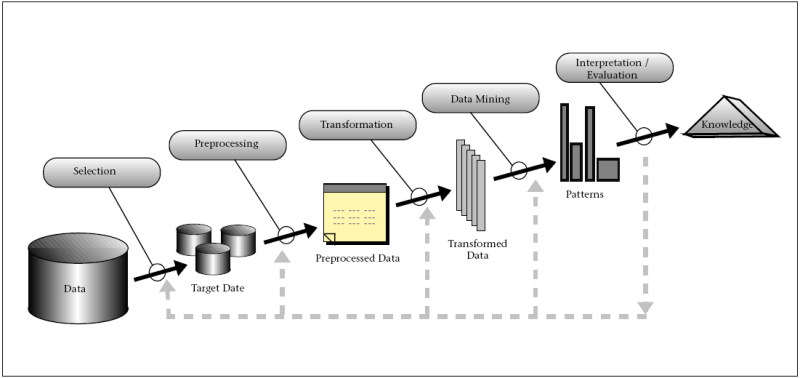
In practice:
- Most of "data mining" is actually "data preprocessing" (hours to days of scripting- learn Bash and Awk/Perl/Python);
- The proces is cyclic. Results, version1, leads to "that's funny" followed by version2, followed by...
Important to review, not blindly accept, the learned theories:
- Toss a coin. At probability
, the next coin toss will be repeated
times. If you toss a coin 100 times, then we would expect at least one sequence of size six. [Courtney85
- Looked at randomly generated numbers in the ranges that would be expected in Halstead's software science measures.
- The average maximum linear correlation for randomly generated numbers is 0.70 (or higher if the sample size is low compared to the number of variables).
Discretization
Group together numbers in a continuous range into a smaller number of discrete bins [41]. In other words, discretization reduces the dimensionality of each term.
Rotation
A matrix T*D has axis along T and D. New axis can be inferred using a variety of techniques including Principal Component Analysis (PCA) [86], Latent Dirichlet Allocation (LDA) [14], and FASTMAP [37]. Geometrically, these new axes fall at some rotation to the original axes. For example, PCA is a vector space transform often used to reduce multidimensional data set to lower dimensions for analysis. PCA involves the calculation of the eigenvalue decomposition of a data covariance matrix or a single value decomposition of, say, a T*D matrix.
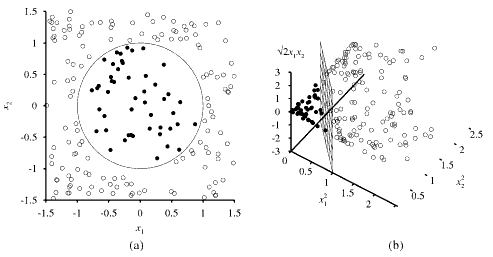
-
A two-dimensional training set with postive examples as black circles and negative
examples as white circles. The decision boundary
is also shown.
-
The same data after mapping into a three-dimensional input space
,
,
.
Note that the circular decision boundary in (a) becomes a linear decision boundary in the three dimensions of (b). From [Russell10].
Projection
In SQL, a project query returns a subset of the columns. In text/data mining, projection operators delete the least informative terms; i.e., it reduces the dimensions of T1*D matrix to T2*D matrix where T2 ! T1. A common technique relies on the Singular Value Decomposition (SVD) [101] of the original matrix. Projection is often a batch process, applied once before any queries are processed [44, 51]. For text mining applications, projection is an essential pre-processing step that proceeds all the other processing since, without projection, we must reason over an intractable number of terms. hard: kernel easy: tfidf
Selection
In SQL, a select query returns a subset of the rows. In text/data mining, select operators select the subset of the data relevant to some current query. That is, selection reduces the dimensions of a T*D1 matrix to T*D2 matrix where D2 ! D1. Selection is very useful for removing outliers and anomalous examples from a reasoning process. Unlike projection, the selection operator may have to be repeated for each new query and so, usually, it can significantly slow down query processing. However, selection can be applied as a batch task, for example, discarding excessive examples of some over-abundant dependent term. This is a useful pre-processor since, as Drummond and Holte report [31], it allows us to learn predictors for rare dependent terms which, otherwise, would be lost in a crowd of other dependent terms. hard: k-means easier: genic discretization