| [ << ] | [ < ] | [ Up ] | [ > ] | [ >> ] | [Top] | [Contents] | [Index] | [ ? ] |
Definitions
Context-Free Grammars
Backus-Naur Form (1959)
Example:
<program> ==> <stmts> <stmts> ==> <stmt> | <stmt> ; <stmts> <stmt> ==> <var> = <expr> <var> ==> a | b | c | d <expr> ==> <term> + <term> | <term> - <term> <term> ==> <var> | const
Example derivation:
<program> => <stmts> => <stmt>
=> <var> = <expr>
=> a = <expr>
=> a = <term> + <term>
=> a = <var> + <term>
=> a = b + <term>
=> a = b + cons
Specifies tokens. One of:
Parentheses are used to avoid ambiguity about where the various sub-expressions start and end.
Consider, for example, the syntax of numeric constants accepted by a simple hand-held calculator:
<number> => <integer> | <real> <integer> => <digit> <digit> * <real> => <integer> <exponent> | <decimal> ( <exponent> | ε ) <decimal> => <digit> * ( . <digit> | <digit> . ) <digit> * <exponent> => ( e | E ) ( + | - | ε ) <integer> <digit> => 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9
A regular expression can be viewed as a finite state automota (FSA) that recognizes (or generates) a valid sentence in a language.
FSAs can be represented as transitions between states
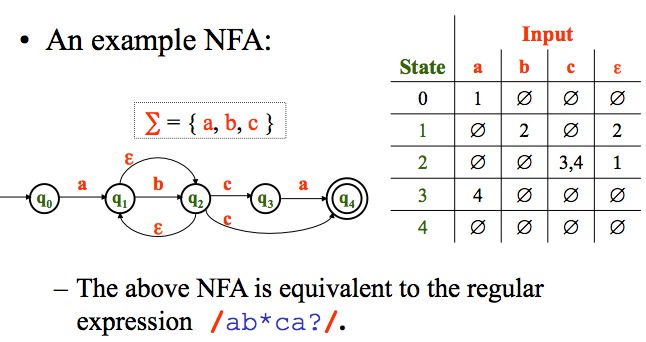
Parser generators build these state transition tables (so that subsequent processing a programming language is very fast).
A hierarchical representation of a derivation
<program>
|
<stmts>
|
<stmt>
/ | \
/ | \
/ | \
<var> "=" <expr>
| / | \
"a" <term> "+" <term>
| |
<var> const
|
"b"
A grammar is "ambiguous" if and only if it generates a sentential form that has two or more distinct parse trees
<expr> ==> <expr> <op> <expr> | const <op> ==> / | -
<expr> <expr>
/ \ \ / | \
/ \ \ / | \
<expr> <op> <expr> <expr> <op> <expr>
/ | \ \ | | | | \ \
/ | \ | | | | | \ \
/ | \ | | | | | \ \
<expr> <op> <expr> | | | | <expr> <op> <expr>
| | | | | | | | | |
const "-" const "/" const const "-" const "/" const
Fix: If we use the parse tree to indicate precedence levels of the operators, we cannot have ambiguity
<expr> ==> <expr> - <term> | <term> <term> ==> <term> / const| const
<expr>
/ | \
<expr> "-" <term>
| | \ \
| | \ \
| | \ \
<term> <term> "/" const
| |
<const> <const>
Operator associativity can also be indicated by a grammar
<expr> ==> <expr> + <expr> | const (ambiguous) <expr> ==> <expr> + const | const (unambiguous
Parse:
<expr>
/ | \
<expr> "+" const
/ | \
<expr> "+" const
|
const
Grammars generate all properly formed expressions in some language but says nothing about their meaning. To tie these expressions to mathematical concepts we need additional notation.
The most common is based on attributes. In our expression grammar, we can associate a val attribute with each E, T, F, and const in the grammar.
The intent is that for any symbol S, S.val will be the meaning, as an arithmetic value, of the token string derived from S. We assume that the val of a const is provided to us by the scanner.
We must then invent a set of rules for each production, to specify how the vals of different symbols are related. The resulting attribute grammar (AG) for a simple calculator is shown here:

Going one step further, the "Parse tree" is a nested set of objects. In this design, each non-terminal is some instance of sub-class of "Grammar". Once a language is parsed, an OO interpreter can execute the parse tree, with each non-terminal handling the specific processing associated with that node.
For example, an if-test would create and instance of class "If" with slots for "expr" and then "then" and "else" actions.
<if> => if <expr> then <action> else <action> fi
To interpret this, the OO interpreter just sends the message "evaluate" to this instance which, in turn, sends "evaluate" to "expr". If that returns true, then the "then" action is messaged with "evaluate". Else, we "evaluate" the "else".
| [ << ] | [ < ] | [ Up ] | [ > ] | [ >> ] | [Top] | [Contents] | [Index] | [ ? ] |
This document was generated on April 19, 2011 using texi2html 5.0.