| [ << ] | [ < ] | [ Up ] | [ > ] | [ >> ] | [Top] | [Contents] | [Index] | [ ? ] |
C-based tool for building compilers.
Generic approach to recongizing parts of an input stream, then performing specific actions for certain sections.
Guard action pairs. Guards defined by regular expressions:
x* = zero or more
x+ = one or more
[abc] = "or". Anyone of "a" or "b" or "c"
\n = new line
\t = new line
%{
#include <stdlib.h>
#include "calc3.h"
#include "y.tab.h"
void yyerror(char *);
%}
%%
[a-z] {
yylval.sIndex = *yytext - 'a';
return VARIABLE;
}
0 {
yylval.iValue = atoi(yytext);
return INTEGER;
}
[1-9][0-9]* {
yylval.iValue = atoi(yytext);
return INTEGER;
}
[-()<>=+*/;{}.] {
return *yytext;
}
">=" return GE;
"<=" return LE;
"==" return EQ;
"!=" return NE;
"while" return WHILE;
"if" return IF;
"else" return ELSE;
"print" return PRINT;
[ \t\n]+ ; /* ignore whitespace */
. yyerror("Unknown character");
%%
int yywrap(void) {
return 1;
}
Regular expression extensions:
[^abc] = negation. Not one of "a" or "b" or "c";
^ = start of line;
$ = end of line;
. = any character;
\x = escaped character. E.g. ""\." is the period character, not any characer.
Scott Pakin. Regular Expressions and Gender Guessing. In Computer Language Magazine, 8(12):pp. 59-68, December 1991.
{ sex = "m" } # Assume male.
/^.*[aeiy]$/ { sex = "f" } # Female names endng in a/e/i/y.
/^All?[iy]((ss?)|z)on$/ { sex = "f" } # Allison (and variations)
/^.*een$/ { sex = "f" } # Cathleen, Eileen, Maureen,...
/^[^S].*r[rv]e?y?$/ { sex = "m" } # Barry, Larry, Perry,...
/^[^G].*v[ei]$/ { sex = "m" } # Clive, Dave, Steve,...
/^[^BD].*(b[iy]|y|via)nn?$/ { sex = "f" } # Carolyn,Gwendolyn,Vivian,...
/^[^AJKLMNP][^o][^eit]*([glrsw]ey|lie)$/ { sex = "m" } # Dewey, Stanley, Wesley,...
/^[^GKSW].*(th|lv)(e[rt])?$/ { sex = "f" } # Heather, Ruth, Velvet,...
/^[CGJWZ][^o][^dnt]*y$/ { sex = "m" } # Gregory, Jeremy, Zachary,...
/^.*[Rlr][abo]y$/ { sex = "m" } # Leroy, Murray, Roy,...
/^[AEHJL].*il.*$/ { sex = "f" } # Abigail, Jill, Lillian,...
/^.*[Jj](o|o?[ae]a?n.*)$/ { sex = "f" } # Janet, Jennifer, Joan,...
/^.*[GRguw][ae]y?ne$/ { sex = "m" } # Duane, Eugene, Rene,...
/^[FLM].*ur(.*[^eotuy])?$/ { sex = "f" } # Fleur, Lauren, Muriel,...
/^[CLMQTV].*[^dl][in]c.*[ey]$/ { sex = "m" } # Lance, Quincy, Vince,...
/^M[aei]r[^tv].*([^cklnos]|([^o]n))$/ { sex = "f" } # Margaret, Marylou, Miriam,...
/^.*[ay][dl]e$/ { sex = "m" } # Clyde, Kyle, Pascale,...
/^[^o]*ke$/ { sex = "m" } # Blake, Luke, Mike,...
/^[CKS]h?(ar[^lst]|ry).+$/ { sex = "f" } # Carol, Karen, Sharon,...
/^[PR]e?a([^dfju]|qu)*[lm]$/ { sex = "f" } # Pam, Pearl, Rachel,...
/^.*[Aa]nn.*$/ { sex = "f" } # Annacarol, Leann, Ruthann,...
/^.*[^cio]ag?h$/ { sex = "f" } # Deborah, Leah, Sarah,...
/^[^EK].*[grsz]h?an(ces)?$/ { sex = "f" } # Frances, Megan, Susan,...
/^[^P]*([Hh]e|[Ee][lt])[^s]*[ey].*[^t]$/ { sex = "f" } # Ethel, Helen, Gretchen,...
/^[^EL].*o(rg?|sh?)?(e|ua)$/ { sex = "m" } # George, Joshua, Theodore,..
/^[DP][eo]?[lr].*se$/ { sex = "f" } # Delores, Doris, Precious,...
/^[^JPSWZ].*[denor]n.*y$/ { sex = "m" } # Anthony, Henry, Rodney,...
/^K[^v]*i.*[mns]$/ { sex = "f" } # Karin, Kim, Kristin,...
/^Br[aou][cd].*[ey]$/ { sex = "m" } # Bradley, Brady, Bruce,...
/^[ACGK].*[deinx][^aor]s$/ { sex = "f" } # Agnes, Alexis, Glynis,...
/^[ILW][aeg][^ir]*e$/ { sex = "m" } # Ignace, Lee, Wallace,...
/^[^AGW][iu][gl].*[drt]$/ { sex = "f" } # Juliet, Mildred, Millicent,...
/^[ABEIUY][euz]?[blr][aeiy]$/ { sex = "m" } # Ari, Bela, Ira,...
/^[EGILP][^eu]*i[ds]$/ { sex = "f" } # Iris, Lois, Phyllis,...
/^[ART][^r]*[dhn]e?y$/ { sex = "m" } # Randy, Timothy, Tony,...
/^[BHL].*i.*[rtxz]$/ { sex = "f" } # Beatriz, Bridget, Harriet,...
/^.*oi?[mn]e$/ { sex = "m" } # Antoine, Jerome, Tyrone,...
/^D.*[mnw].*[iy]$/ { sex = "m" } # Danny, Demetri, Dondi,...
/^[^BG](e[rst]|ha)[^il]*e$/ { sex = "m" } # Pete, Serge, Shane,...
/^[ADFGIM][^r]*([bg]e[lr]|il|wn)$/ { sex = "f" } # Angel, Gail, Isabel,...
{ print sex } # Output prediction
Input langauge
label here's some stuff bottom ticks 1 5 10 left ticks 1 2 10 20 range 1 1 10 22 height 10 width 30 1 2 * 2 4 * 3 6 * 4 8 * 7 14 + 8 12 + 9 10 + mb 0.9 11 =
Output example:
|----------------------|
20 - = = =
| = = = = |
= = = + + |
10 - + |
| * * |
| * |
2 *---------|------------|
1 5 10
here's some stuff
The code is here. Note the use of guard action pairs, where the guards are regular expressions.
(From a page by Russ Cox.)
Strange to say, many modern languages use a simplistic recursive descent test for regular expressions.
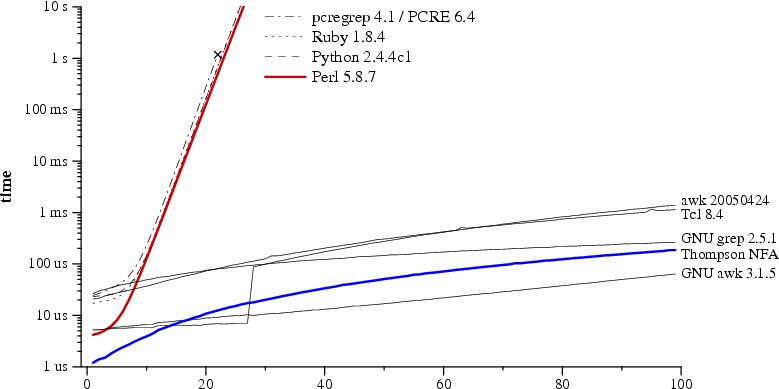
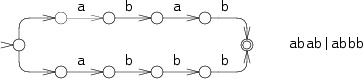
e.g. Lets build two finate state automoa for the patterhn abab|abbb and run it the string abbb.
First, the dumb way:
A more efficient but more complicated way to simulate perfect guessing is to guess both options simultaneously. In this approach, the simulation allows the machine to be in multiple states at once. To process each letter, it advances all the states along all the arrows that match the letter.
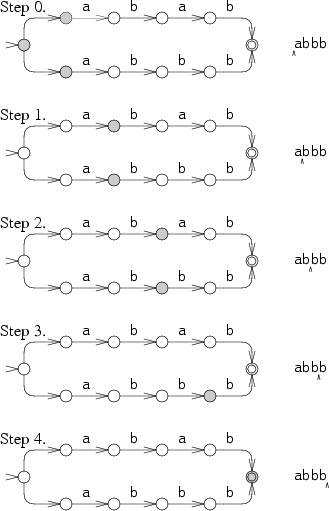
Note that this second way was first implemented by Ken Thompson introduced the multiple-state simulation approach in his 1968 paper. The full source code (under 400 lines) and the benchmarking scripts are available online
Thompson introduced his regualr expression to programmers in his implementation of the text editor QED for CTSS. Dennis Ritchie followed suit in his own implementation of QED, for GE-TSS. Thompson and Ritchie would go on to create Unix, and they brought regular expressions with them. By the late 1970s, regular expressions were a key feature of the Unix landscape, in tools such as ed, sed, grep, egrep, awk, and lex.
Remember that OCaml language? That was strongly typed (at compile time, you know if a variable is a string, number, whatever) and supported type inferencing (so you can check if you are doing dumb things like adding a number to a string).
Well, OCaml supports recursive type definitions? So that OCaml’s types are a grammar.
type paragraph =
Normal of par_text
| Pre of string * string option
| Heading of int * par_text
| Quote of paragraph list
| Ulist of paragraph list * paragraph list list
| Olist of paragraph list * paragraph list list
and par_text = text list
and text =
Text of string
| Emph of string
| Bold of string
| Struck of par_text
| Code of string
| Link of href
| Anchor of string
| Image of img_ref
and href = { href_target : string; href_desc : string; }
and img_ref = { img_src : string; img_alt : string; }
The Ulist and Olist constructors take the first item followed by a (possible empty) list of items, to prevent empty lists — this way, there’s at least one element.
So eigenclass.org uses the above to define a cool generator for HTML pages using a set of short-cuts:
{{
whatever
}}
{{extension-name blocks; for instance, raw HTML is inserted with
{{html
<b> whatever </b>
}}
(before you try to inject arbitrary HTML in the comments: this extension is only enabled in the main text).
The above grammar is the core of a parser that generates HTML. And, interestingly, in this ultra-high level language, this parse runs very very fast.
runtimes memory
----------------------------- -------------
LoCs README.1 README.8 README.32 README.32 MEM
discount C ~4500 0.016s 0.063s 2.8MB
Bluecloth Ruby 1100 0.130s 2.16s 30s 31MB
markdown Perl 1400 0.068s 0.66s segfault segfault
python-markdown Python 1900 0.090s 0.35s 2.06s 23MB
Pandoc Haskell 900 + 450 0.068s 0.55s 2.7s 25MB
----------------------------------------------------------------------------------
Simple_markup OCaml 313 + 55 0.012s 0.043s 3.5MB
So, in the 21st century, you can have you cake and eat it too:
| [ << ] | [ < ] | [ Up ] | [ > ] | [ >> ] | [Top] | [Contents] | [Index] | [ ? ] |
This document was generated on April 19, 2011 using texi2html 5.0.