| [ << ] | [ < ] | [ Up ] | [ > ] | [ >> ] | [Top] | [Contents] | [Index] | [ ? ] |
(Reference: Science, 20 June 1980, Vol. 208. no. 4450, pp. 1335 - 1342 "Expert and Novice Performance in Solving Physics Problems", Jill Larkin, John McDermott, Dorothea P. Simon, and Herbert A. Simon. )
Much of the early AI research was informed by a cognitive psychology model of human expertise. The model has two parts:
Reasoning was, according to this mode: a match-act cycle:
In this model
Q: How to experts know what is relevant?
A: feature extractors- gizmos that experts learn to let them glance at a situation and extract the salient details. E.g. chess experts can reproduce form memory all the positions on a chess board But if you show the same experts a gibberish game (one where all the rules are broken- e.g white pawns on white’s back row) then they can’t reproduce the board. Why? Well, when they glance at a board, their feature extractors fire to offer them a succinct summary. Gibberish boards baffle the feature extractors, so no summary
Much, much work on mapping this cognitive psychological insight into AI programs
(Reference: "An Expert System for Raising Pigs" by T.J. Menzies and J. Black and J. Fleming and M. Dean. The first Conference on Practical Applications of Prolog 1992 . Available from http://menzies.us/pdf/ukapril92.pdf )
PIGE: Australia’s first exported rule-based expert systems
Written by me, 1987 who trapped the expertise of pig nutritionists in a few hundred rules.
PIGE would find factors to control, try them on a simulator of a farm, then adjust its factors accordingly.
Here’s PIGE out-performing the experts:

Why did PIGE success so well? Limits to short-term-memory. PIGE had none. The humans, on the other hand, had the standard human limitations
( V.L. Yu and L.M. Fagan and S.M. Wraith and W.J. Clancey and A.C. Scott and J.F. Hanigan and R.L. Blum and B.G. Buchanan and S.N. Cohen, 1979, Antimicrobial Selection by a Computer: a Blinded Evaluation by Infectious Disease Experts, Journal of American Medical Association, vo. 242, pages 1279-1282)
Given patient symptoms, what antibiotics should be prescribed?
Approx 500 rules.
Extensively studied:
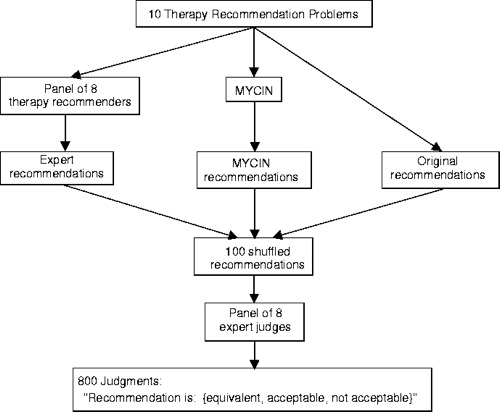
Compared to humans, performed very well:

Why did it perform so well?
John McDermott, DEC, 1980s. Two systems:
With strong theoretical support and excellent industrial case studies, the future for AI seemed bright.
Begin the AI summer (mid-1980s). Just like the Internet bubble of 2000: fledgling technology, over-hyped, immature tool kits.
And after the summer, came the fall. Enough said.
Happily, then came the 1990s, data mining, and results from real-time AI planners, and stochastic theorem provers.
By 2003, I could say I was an AI-nerd and people would not run away.
Here’s a good introduction on rule-based programming. Read it (only pages 1,2,3,4,5,6,7) carefully to learn the meaning of:
Backward chaining supports how and why queries:
Forward chaining supports only how not why.
Define match, resolve, act
(Note: BAGGER is a toy example of how XCON configured computers.)
Some nice advantages for software engineering:
And guess what- all this was code with rules!
As rule-based programs became more elaborate, their support tools more intricate, the likelihood that they had any human psychological connection became less and less.
As we built larger and larger rule bases, other non-cognitive issues became apparent:
Note that both these problems come from the global nature of match: all rules over all working memory.
Go to simpler representations. e.g. state machines (used in gaming, next lecture)
As used in many rule-based tools including OPS5, ART, JESS. Compile all the rules into a big network wiring all the conditions together.

RETE supports standard resolution operators: e.g.:
Note: RETE changes some constant time factors in the search but does not tame the fundamental problem of all rules looking in all places all the time.
If searching/understanding all is too much, find ways to built the whole from local parts. Have separate rule bases for each part.
Q: How to divide the system?
A1: Using domain knowledge; e.g. from [Tambe91]:
A2: using background knowledge of problem solving types. Add tiny little specialized rule bases to the implement knowledge-level operators.
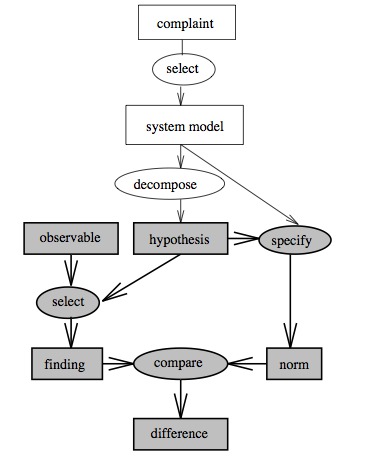
E.g. here’s Clancy’s abstraction of MYCIN:

And here’s his abstraction of an electrical fault localization expert system:

Note that the same abstract problem solving method occurs in both
A whole mini-industry arose in the late 1980s, early 1990s defining libraries of supposedly reusable problem solving methods.
e.g. Here’s "diagnosis"
Here’s "monitoring":
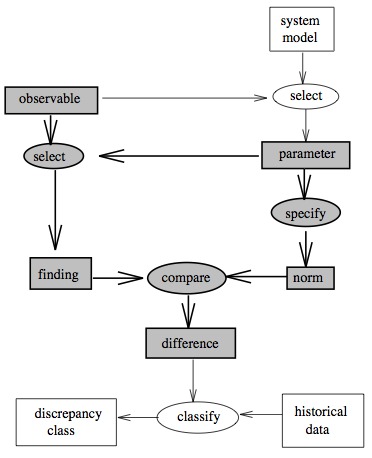
Note that you could write and reuse rules based to handle select, compare, specify.
And there’s some evidence that this is useful. Marcus and McDermott built rule bases containing 7000+ rules via role-limiting methods. That is, once they knew their problem solving methods, they write specialized editors that only let users enter in the control facts needed to just run those methods.
For a catalog of problem solving methods, see Cognitive Patterns By Karen M. Gardner (contributors James Odell, Barry McGibbon), 1998, Cambridge University Press
| [ << ] | [ < ] | [ Up ] | [ > ] | [ >> ] | [Top] | [Contents] | [Index] | [ ? ] |
This document was generated on March 1, 2011 using texi2html 5.0.